 CS 662: Theory of Parallel Algorithms
CS 662: Theory of Parallel Algorithms
Spring Semester 1995
Introduction
San Diego State University -- This page last updated January 29, 1995

- Introduction
- What is Parallelism in Computers?
- Common Terms for Parallelism
- Parallel Programming
- Parallel Machines
- Type and number of processors
- Processor interconnections
- Global Control
- Synchronous vs. Asynchronous Operation
- Parallel Algorithms-Models of Computation
- PRAM
- Metrics
Parallelism is a digital computer performing more than one task at the same
time
Examples
IO chips
- Most computers contain special circuits for IO devices which allow some
task to be performed in parallel
Pipelining of Instructions
- Some cpu's pipeline the execution of instructions
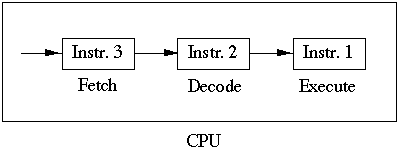
Multiple Arithmetic units (AU)
- Some CPUs contain multiple AU so it can perform more than one arithmetic
operation at the same time
We are interested in parallelism involving more than multiple CPUs
Concurrent Processing
- A program is divided into multiple processes which are run on a single
processor
-
- The processes are time sliced on the single processor
Distributed Processing
- A program is divided into multiple processes which are run on multiple
distinct machines
-
- The multiple machines are usual connected by a LAN
-
- Machines used typically are workstations running multiple programs
Parallel Processing
- A program is divided into multiple processes which are run on multiple
processors
-
- The processors normally:
- are in one machine
- execute one program at a time
- have high speed communications between them
Some Timing Results
Time to send 100 integers between 2 processes
Concurrent: on Saturn .029 milliseconds
Distributed: Saturn & Rohan 20.0 milliseconds
Distributed: Saturn & East Coast 41.4 milliseconds
Intel Paragon Message Passing Time
Old New
Latency 100 microsec 40 microsec
Throughput 30MByte/sec 200MByte/sec
Issues in parallel programming not found in sequential programming
- Task decomposition, allocation and sequencing
- Breaking down the problem into smaller tasks (processes) than can be run in
parallel
-
- Allocating the parallel tasks to different processors
-
- Sequencing the tasks in the proper order
-
- Efficiently use the processors
- Communication of interim results between processors
- The goal is to reduce the cost of communication between processors. Task
decomposition and allocation affect communication costs
- Synchronization of processes
- Some processes must wait at predetermined points for results from other
processes.
- Different machine architectures
Performance Issues
- Using more nodes should
- allow a job to run faster
-
- allow a larger job to run in the same time
- All nodes should have the same amount of work
-
- Avoid having nodes idle while others are computing
- Communication bottlenecks
- Nodes spend too much time passing messages
-
- Too many messages are traveling on the same path
- Serial bottlenecks
- Message passing is slower than computation
-
- Maximize computation per message
-
- Avoid making nodes wait for messages
-
-
-
- L = latency time to start a message
-
- Tr = transmission time per byte of information
-
- N = number of bytes in message
-
- Time = time to send message
- Time = L + N*Tr
Values for Paragon
Old New
L 100 microseconds 40 microseconds
Tr 30 MBytes/sec 200 MBytes/sec
Parameters used to describe or classify parallel computers:
- Type and number of processors
- Processor interconnections
- Synchronous vs. asynchronous operation
The Extremes
Massively parallel
- Computer systems with thousands of processors
-
- Parallel Supercomputers
-
- CM-5, Intel Paragon
Coarse-grained parallelism
- Few (~10) processor, usually high powered in system
-
- Starting to be common in Unix workstations
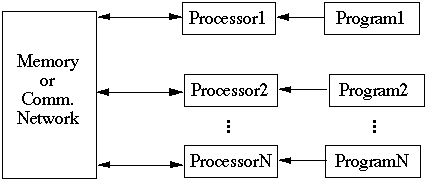
Parallel computers may be loosely divided into two groups:
- Shared Memory (or Multiprocessor)
- Message Passing (or Multicomputers)
Shared Memory or Multiprocessor
Individual processors have access to a common shared memory module(s)
Examples
- Alliant, Cray series, some Sun workstations
Features
- Easy to build and program
- Limited to a small number of processors
- 20 - 30 for Bus based multiprocessor
Bus Based Multiprocessor 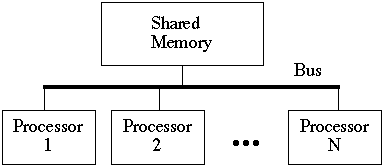
Processor-Memory Interconnection Network
Multiprocessor
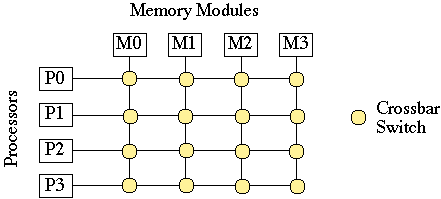
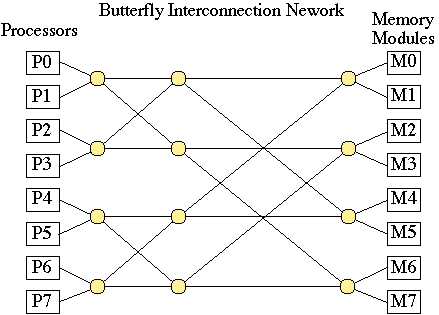
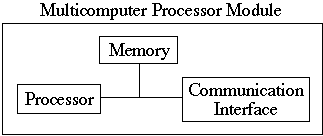
Message Passing or Multicomputers
Individual processors local memory.
Processors communicate via a communication network
Examples
- Connection Machine series (CM-2, CM-5), Intel Paragon, nCube, Transputers,
Cosmic Cube
Features
- Can scale to thousands of processors
Mesh Communication Network
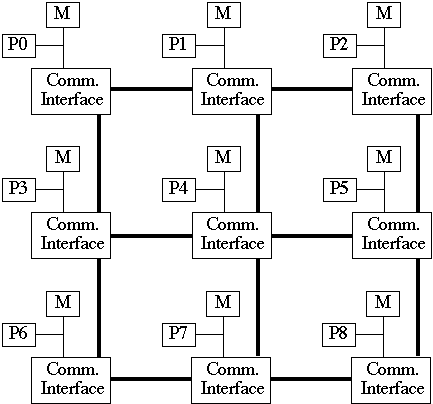
Intel Paragon is a mesh machine
or SISD, SIMD, MIMD, MISD
SISD - Single Instruction Single Data
- Sequential Computer

MISD - Multiple Instruction Single Data
- Each processor can do different things to the same input
-
- Example: Detect shapes in an image.
- Each processor searches for a different shape in the input image
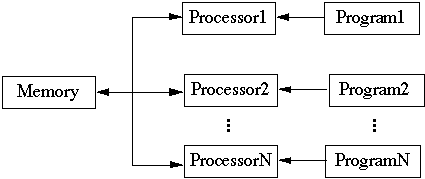
Global Control
SIMD - Single Instruction Multiple Data
- Each processor does the same thing to different data
-
- Requires global synchronization mechanism
-
- Each processor knows its id number
-
- Not all shared memory computers are SIMD
- Example: Adding two arrays A and B.
- in Parallel do: K
- Read A[K] and B[K]
- Write A[K] + B[K] in C[K]
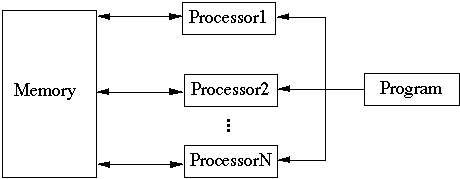
Global Control
MIMD -Multiple Instruction Multiple Data
- Each processor can run different programs on different data
-
- MIMD can be shared memory or message passing
-
- Can simulate SIMD or SISD if there is global synchronization mechanism
-
- Communication is the main issue
-
- Harder to program than SIMD
Does the computer have a common global clock to synchronize the operation of
the different processors
Shared memory and message passing computers can be synchronous
Parallel Random-Access Machine
Most commonly used model for expressing parallel algorithms
- Each processor may have local memory to store local results
- Model is MIMD, but algorithms tend to be SIMD
-
- Each active processor executes same instruction
- Exclusive Read Exclusive Write (EREW) - no simultaneous access to a single
shared-memory location
-
-
- Concurrent Read Exclusive Write (CREW) - simultaneous reads of a single
shared-memory location are allowed
-
-
- Concurrent Read Concurrent Write (CRCW) - simultaneous reads and writes are
allowed on a single shared-memory location are allowed
- Handling concurrent writes
- Common CRCW PRAM allows concurrent writes only when all processors are
writing the same value
-
- Arbitrary CRCW PRAM allows an arbitrary processor to succeed at writing to
the memory location
-
- Priority CRCW PRAM allows the processor with minimum index to
succeed
Examples
read(X, Y) copy X from shared memory to local memory Y
write(U, V) copy U from local memory to local memory V
Testing Primeness - CRCW
All Processors must write the same value
Input:
- x an integer in shared memory
- k = processor id in local memory
Output:
- Result in shared memory
for k = 1 to n do in parallel
write(1, Result)
read(x, test)
if (k divides test) then write(0, Result)
end for
Broadcasting - EREW
Input:
- D - an item in shared memory to be broadcast to all processors
-
- A[n] - an array in shared memory
- n - number of processors
- k = processor id
Result:
- Processors will have copy of D in local memory
if k = 1 then
read(D, d)
write(d, A[1])
end if
for j = 0 to log(n) - 1 do
for k = 2j + 1 to 2j+1 do in parallel
read(A[k - 2j], d)
write(d, A[k])
end for
end for
Time complexity is [[Theta]](log(N))
Some definitions:
-
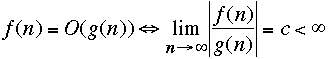
-
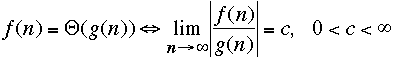
-
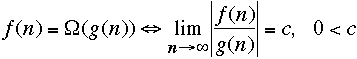
-
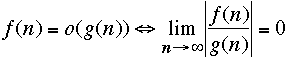
We should define O(g) as
-
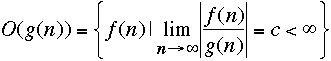
and write
-
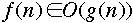
instead of
-
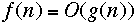
Review of Complexity
Counting operations - Unit cost model
Functions verses orders of magnitude
Common orders of magnitude
Counting operations and communication costs
Upper bounds, lower bounds
Worst case, average case
Important Measures
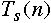 time required by best sequential algorithm to solve a problem of size N
time required by best sequential algorithm to solve a problem of size N
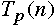 time required by parallel algorithm using p
processors to solve a problem of size N
time required by parallel algorithm using p
processors to solve a problem of size N
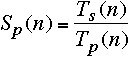 speedup of the parallel algorithm
speedup of the parallel algorithm
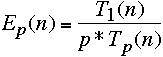 efficiency of the parallel algorithm
efficiency of the parallel algorithm
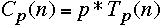 cost of the parallel algorithm
cost of the parallel algorithm
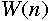 = the number of total operations done by the parallel algorithm
= the number of total operations done by the parallel algorithm
Example of Measures
Adding N integers with P processors
A[1..N] is array in shared memory holding values to add
Algorithm 1 P = N/2, N is a power of 2
J = N/2
while J >= 1 do
for K = 1 to J do in Parallel
Processor K: A[K] = A[2K-1]+A[2K]
end for
J = J/2
end while
Algorithm 2
for I = 1 to P do in Parallel
Processor I: A[I] = A[{(I-1)*N/P}+1] +
A[{(I-1)*N/P}+2] + ... +
A[(I)*N/P]
end for
J = N/2
while J >= 1 do
for K = 1 to J do in Parallel
Processor K: A[K] = A[2K-1]+A[2K]
end for
J = J/2
end while